- Published on
Bloque 02 — Preparación de Datos en SAS (Data Step, PROC Step, Importación y Calidad)
- Authors

- Name
- Cristina Chapoñan Chamorro
- X
- @Cristina_CCC
Datos a la vista
Introducción
En este bloque abordaremos los fundamentos de la preparación y limpieza de datos en SAS. Combinaremos teoría básica con prácticas interactivas, manteniendo un nivel técnico intermedio. Al final, los participantes comprenderán las diferencias entre los pasos DATA y PROC en SAS, sabrán cargar datos desde archivos externos en SAS Studio (OnDemand), y aplicarán técnicas básicas de limpieza y validación de datos. Este conocimiento es esencial para asegurar que los datos estén precisos, consistentes y listos para análisis.
1. Data Step vs. PROC Step en SAS
SAS organiza sus programas en dos tipos de bloques: pasos DATA (para crear y transformar datos) y pasos PROC (para análisis, reportes y otras operaciones sobre datos existentes). A continuación, se resumen diferencias, usos típicos y buenas prácticas.
Paso DATA (Data Step): Es el bloque donde se crean o modifican conjuntos de datos (datasets). Se inicia con la instrucción DATA NombreDataset; y permite tareas como lectura de datos, creación de variables nuevas, recodificación, filtrado de registros y otras transformaciones. Cada vez que se ejecuta un paso DATA, SAS genera un dataset nuevo (o reemplaza uno existente) con el nombre especificado. El procesamiento en un paso DATA es generalmente secuencial, iterando por cada observación (fila) una a una, a menos que se utilicen funciones especiales. Ejemplos de uso: importar datos crudos, calcular columnas derivadas, combinar datasets, filtrar observaciones.
Paso PROC (Procedure Step): Es el bloque que invoca un procedimiento predefinido de SAS para analizar o procesar datos existentes sin modificar su estructura. Comienza con PROC NombreProcedimiento; y suele incluir opciones o subinstrucciones. Las PROC realizan tareas como análisis estadísticos, generación de tablas o reportes, ordenamiento de datos, cálculos resumidos y graficación. A diferencia del paso DATA, en un PROC no se crean datasets nuevos por defecto (salvo que el procedimiento tenga una opción OUTPUT), sino que se trabaja sobre datos ya existentes y se producen resultados (salida en pantalla, gráficos, listados, etc.). Ejemplos de uso: PROC SORT (ordena datos), PROC MEANS (estadísticos descriptivos), PROC FREQ (tablas de frecuencia), PROC PRINT (listar datos), PROC SQL, etc.
Principales diferencias: Un paso DATA es programable y flexible, permite manipular datos registro por registro y generar nuevos conjuntos de datos. Un paso PROC ejecuta rutinas optimizadas de SAS para tareas específicas sobre el dataset completo. Por ejemplo, podríamos calcular estadísticas agregadas mediante un bucle en un paso DATA, pero es más sencillo usar PROC MEANS o PROC SQL para operar sobre todos los registros a la vez. Asimismo, ciertas transformaciones solo pueden hacerse en pasos DATA (p. ej., lectura personalizada de archivos, transformaciones fila a fila), mientras que muchas analíticas y operaciones eficientes ya están implementadas en procedimientos. En la práctica, ambos tipos de pasos se combinan: se utiliza el paso DATA para preparar los datos y los pasos PROC para analizarlos o reportarlos. Un programa SAS típico alterna entre pasos DATA y PROC, cada bloque terminado por una instrucción RUN; (o implícitamente al iniciar el siguiente bloque).
Persistencia de cambios: Las instrucciones dentro de un PROC no alteran permanentemente el dataset, a menos que el PROC específicamente cree una salida (por ejemplo, PROC SORT con la opción OUT= o sin OUT que sobreescribe el dataset ordenado). En cambio, en un paso DATA sí podemos guardar cambios directamente en un nuevo dataset. Nota: Es posible aplicar formateos o etiquetas temporales dentro de un PROC, pero estos no se guardan en el dataset, mientras que si se aplican en un paso DATA pasan a formar parte de las propiedades del dataset (más detalles sobre formatos abajo).
Ejemplo integrado: Supongamos que tenemos datos crudos en texto y deseamos generar un informe sencillo. Primero usaríamos un paso DATA para leer el archivo y limpiarlo:
/* Ejemplo integrado usando nuestros datos del curso */
PROC IMPORT DATAFILE="/home/usuario/datos_curso_sas.csv"
OUT=work.datos
DBMS=csv
REPLACE;
GETNAMES=YES;
DATAROW=2;
RUN;
/* Verificar la importación y mostrar estadísticas básicas */
PROC MEANS DATA=work.datos N MEAN MAXDEC=2;
VAR monto edad salario;
TITLE 'Estadísticas básicas de variables numéricas';
RUN;
/* Mostrar primeros 5 registros */
PROC PRINT DATA=work.datos (OBS=5);
TITLE 'Primeros 5 registros del dataset';
RUN;
Aquí creamos el dataset VENTAS leyendo un CSV con delimitador coma y aplicamos un formato de fecha. Luego, calculamos estadísticas básicas del campo monto y listamos las primeras 5 observaciones. Cada PROC toma el dataset generado y produce resultados sin modificarlo.
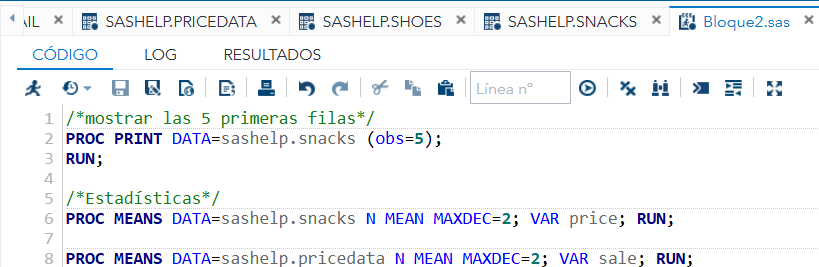 Figura 1. Ilustración de la alternancia entre pasos DATA y PROC en un programa SAS (visión general).
Figura 1. Ilustración de la alternancia entre pasos DATA y PROC en un programa SAS (visión general).Referencias recomendadas — Estructura de programas en SAS
How the DATA Step Works (SAS Help Center) — Explica fases de compilación y > ejecución del DATA step con ejemplos.
Enlace: https://documentation.sas.com/doc/en/basess/9.4/n053a58fwk57v7n14h8x7y7u34y4.> htmAbout the PROC Step (SAS Help Center) — Describe la estructura de los pasos PROC y > sus sentencias/opciones.
Enlace: https://documentation.sas.com/doc/en/grstatproc/latest/> p15w7pav2htadsn1pvwlbm2t7ca7.htmManual de Introducción a SAS System® v9.4 (UAB) — Cap. 2 — Revisión en español de > la composición de programas SAS con bloques DATA y PROC.
Enlace: https://www.uab.cat/ca/servei-estadistica-aplicada/doc/manualintroducciosas.pdfBlog SAS Users — “Data Step or PROC? It depends…” (Ron Cody, 2023) — Comparativa > práctica entre DATA step y PROC para tareas equivalentes y consideraciones de > rendimiento.
Enlace: https://blogs.sas.com/content/sgf/2023/02/22/data-step-or-proc-it-depends/SAS Communities — Foro Programming — Preguntas y discusiones de usuarios sobre > buenas prácticas y dudas frecuentes.
Enlace: https://communities.sas.com/t5/SAS-Programming/bd-p/programming
2. Carga de datos desde Excel o CSV en SAS Studio (OnDemand)
En esta sección cubrimos cómo importar datos externos (Excel, CSV) en SAS Studio dentro de SAS OnDemand for Academics (entorno gratuito en la nube). Asumimos que ya tienen acceso a SAS OnDemand y SAS Studio. Presentaremos dos enfoques: mediante la interfaz point-and-click (Import Wizard) y mediante código SAS (PROC IMPORT), resaltando consideraciones especiales de SAS OnDemand.
Paso previo – Subir archivos al servidor: SAS OnDemand funciona en la nube, por lo que primero debemos cargar el archivo Excel/CSV desde la PC del usuario al repositorio de SAS Studio. El proceso típico es:
- Guardar el archivo en tu computadora local.
- Iniciar sesión en SAS OnDemand y abrir SAS Studio.
- En SAS Studio, en el panel izquierdo (Servidor de Archivos y Carpetas), seleccionar o crear una carpeta dentro de Files (Home) donde subir el archivo.
- Usar el ícono de “Upload” (flecha hacia arriba) para seleccionar el archivo Excel/CSV y subirlo.
- Verificar que el archivo aparece en la carpeta seleccionada. (Este proceso se puede demostrar en vivo con una captura de pantalla de la interfaz de SAS Studio mostrando el diálogo de subida de archivos).
Haz clic en el ícono  Figura 2. Ícono “Upload” de SAS Studio para subir archivos al panel Files (Home).
Figura 2. Ícono “Upload” de SAS Studio para subir archivos al panel Files (Home).
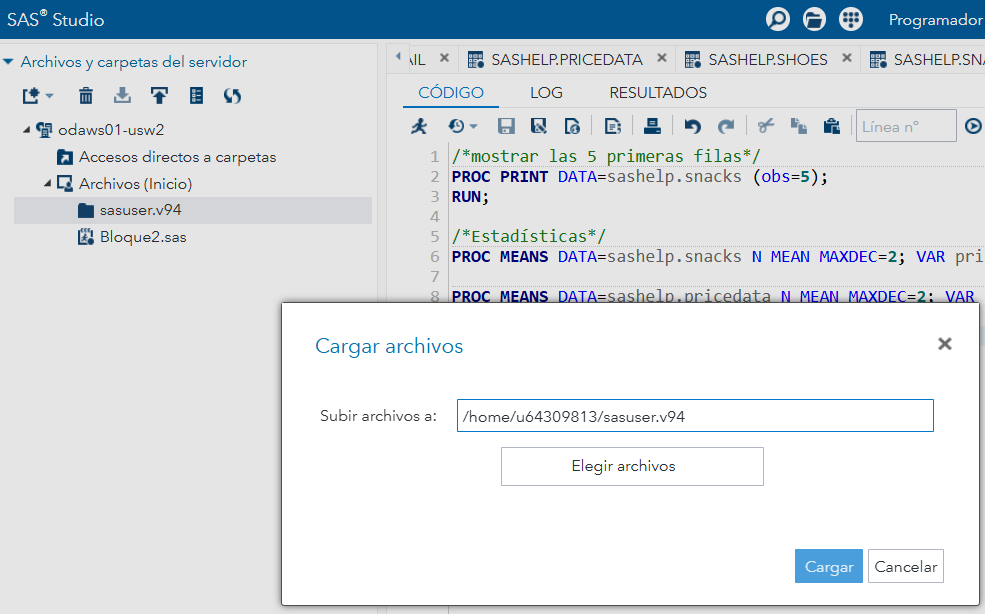 Figura 3. SAS Studio: carpeta de destino y diálogo de subida de archivo (seleccionar Excel/CSV).
Figura 3. SAS Studio: carpeta de destino y diálogo de subida de archivo (seleccionar Excel/CSV). 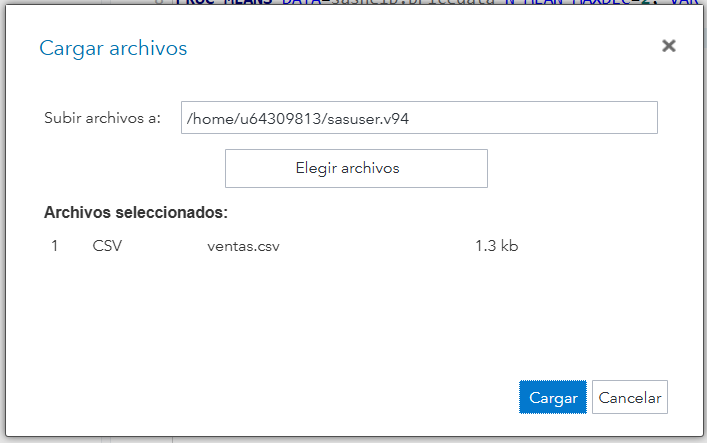 Figura 4. Asistente de importación: elección del archivo fuente y detección del tipo (Excel/CSV).
Figura 4. Asistente de importación: elección del archivo fuente y detección del tipo (Excel/CSV). 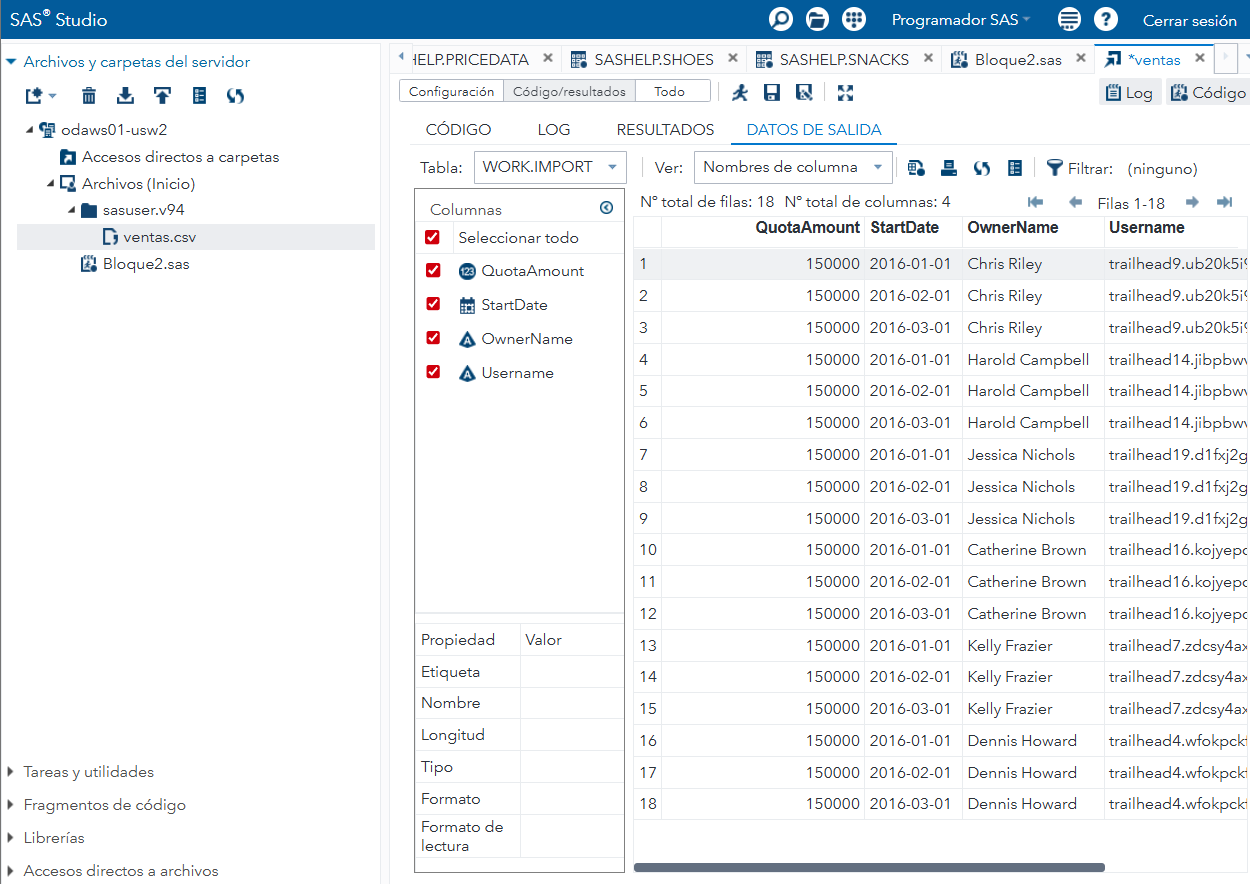 Figura 5. Asistente de importación: opciones de hoja/encabezados y nombre del dataset de salida.
Figura 5. Asistente de importación: opciones de hoja/encabezados y nombre del dataset de salida.Importación mediante el asistente (Import Wizard): SAS Studio provee una forma sencilla de importar datos sin escribir código. Tras subir el archivo:
Ir al menú File → Import Data (o botón Import Data si está visible).
En la ventana del asistente, navegar hasta el archivo (Browse) y seleccionarlo. SAS detectará el tipo (Excel, CSV, etc.) según la extensión.
Especificar opciones: por ejemplo, en Excel elegir qué hoja leer (Sheet), en CSV especificar delimitador si no es coma. Generalmente se puede dejar la opción por defecto de que los nombres de columna están en la primera fila.
Proporcionar un nombre para el dataset de salida SAS (por defecto será WORK.IMPORT u otro; podemos cambiarlo, p. ej., WORK.VENTAS2023).
Clic en Finish. SAS importará el archivo y creará el dataset, mostrando el código equivalente en una pestaña (Import.ctl) para referencia.
Nota: En SAS OnDemand, el asistente soporta formatos Excel (.xls, .xlsx) y texto (.csv, .txt). Si el archivo Excel tiene varias hojas, debemos repetir la importación por cada hoja que necesitemos. Este método es cómodo para iniciarse, pero es importante guardar el código generado para reproducibilidad.
- Importación mediante código (PROC IMPORT): Para mayor control o automatización, podemos usar la instrucción PROC IMPORT en el editor de código SAS. Esta es la sintaxis general:
/* Importación del dataset del curso */
PROC IMPORT DATAFILE="/home/usuario/datos_curso_sas.csv"
OUT=work.datos
DBMS=csv
REPLACE;
GETNAMES=YES;
DATAROW=2;
RUN;
/* Verificar la importación */
PROC CONTENTS DATA=work.datos SHORT;
TITLE 'Estructura del dataset importado';
RUN;
/* Para Excel, usar este código alternativo: */
/* PROC IMPORT DATAFILE="/home/usuario/datos_curso_sas.xlsx" */
/* OUT=work.datos */
/* DBMS=xlsx */
/* REPLACE; */
/* SHEET="DatosCurso"; */
/* GETNAMES=YES; */
/* DATAROW=2; */
/* RUN; */
En este ejemplo, DATAFILE= indica la ruta (en SAS OnDemand normalmente "/home/usuario/folder/archivo.csv"), OUT= es el nombre del dataset SAS a crear, DBMS= especifica el tipo de archivo (csv, xlsx, xls, etc.), REPLACE permite sobrescribir el dataset SAS si ya existía, GETNAMES=YES indica que tome los nombres de variable de la primera fila (en CSV/Excel), y DATAROW=2 en CSV indicaría que los datos empiezan en la fila 2 (fila 1 son nombres). Para archivos Excel usaríamos DBMS=xlsx (o excel según la versión) y, opcionalmente, SHEET= para especificar la hoja.
Tras ejecutar PROC IMPORT, el nuevo dataset aparecerá en la biblioteca WORK (temporal) u otra librería si se indicó. Podemos entonces hacer PROC PRINT o explorar el dataset en SAS Studio (clic derecho > View). Visual sugerido: mostrar un snippet de código PROC IMPORT para un archivo de ejemplo (ej. PROC IMPORT DATAFILE="cartera.xlsx" OUT=work.cartera DBMS=xlsx REPLACE; RUN; ) junto a la explicación de cada opción.
Opciones avanzadas y diferencias: Con PROC IMPORT es posible ajustar opciones como GUESSINGROWS (para CSV: cuántas filas leer para inferir tipos de datos), DATASOURCE= (propiedades avanzadas de Excel) o especificar informats/formatos manualmente después de la importación si algo no quedó correcto. El Import Wizard por su parte infiere automáticamente tipos (p. ej., si una columna en Excel tiene números y algunos textos, puede importarla como carácter). Recomendación: siempre verificar el resultado con PROC CONTENTS (muestra nombres de variables, tipos y formatos asignados). Por ejemplo, asegurarse de que variables numéricas no fueron importadas como texto o viceversa. Si hay discrepancias, posiblemente habrá que convertir tipos en un paso DATA posterior (ver sección de limpieza) o utilizar opciones de GUESSINGROWS más altas en PROC IMPORT para mejorar la detección de tipos.
Importar múltiples archivos o automatizar: Si se tienen muchos archivos a importar, conviene usar código (quizá con macros) en lugar del asistente. Una estrategia común es utilizar una biblioteca (LIBNAME) para Excel: SAS permite asignar un Excel entero como librería (usando LIBNAME excel), de forma que cada hoja es un dataset legible. Sin embargo, en SAS OnDemand puede haber limitaciones en soporte de engines para Excel; una alternativa es convertir Excel a CSV antes de la carga. Para bases de datos relacionales, SAS OnDemand también permite conexiones LIBNAME a PostgreSQL, MySQL, etc., pero esto excede nuestro alcance introductorio.
Recursos
- (a) Página de ayuda de SAS — Importing Data in SAS Studio (OnDemand): Importing Data (SAS Studio User’s Guide)
- (b) Tutorial en video — Importar datos con el Import Data Utility: Using the Import Data Utility in SAS Studio
- (c) Documentación de referencia — PROC IMPORT (SAS Help Center): PROC IMPORT Statement
- (d) Comunidades SAS — Importación en OnDemand: Three Simple Ways to Import Data Into SAS OnDemand for Academics
3. Limpieza de datos básica en SAS
Una vez los datos están en SAS, es crucial realizar limpieza básica antes de cualquier análisis. Abordaremos tres aspectos: manejo de valores faltantes, aplicación de formatos y uso de filtros para subsetting. Introduciremos también algunas funciones útiles. El objetivo es mejorar la calidad de los datos y su presentación, detectando potenciales problemas iniciales.
Tratamiento de valores faltantes (missing values): En SAS, los valores faltantes se representan de manera especial: las variables numéricas muestran un . (punto) como valor missing, mientras que las variables carácter muestran una cadena vacía (blank). Es importante reconocerlos porque muchas funciones y procedimientos de SAS los tratan de forma distinta que a los ceros o cadenas vacías convencionales. Por ejemplo, las funciones estadísticas ignoran los valores missing en sus cálculos (no los cuentan) y, si todos los valores de una lista son faltantes, la función retorna missing. Así, SUM(var1, var2) en SAS sumará solo los valores no faltantes, mientras que el operador aritmético var1 + var2 daría . si cualquiera de los dos es .. Durante la limpieza, se deben tomar decisiones respecto a los missing: ¿se pueden dejar así?, ¿se imputan o reemplazan?, ¿o se filtran registros incompletos? Las estrategias comunes incluyen:
Eliminación de casos con missing: si la proporción es baja, a veces se eliminan registros que tengan datos faltantes en las variables clave. (Cuidado: eliminar muchos casos puede sesgar el análisis si los datos no están MCAR, Missing Completely At Random).
Imputación simple: reemplazar missing por algún estimador como la media, mediana o un valor fijo. Ejemplo: reemplazar edades faltantes con la mediana de edades. Esta opción evita perder registros pero puede reducir la variabilidad real de los datos.
Dejar missing con manejo especial: en algunos análisis, se mantienen los missing pero se usa una categoría especial “Missing” o se utilizan métodos estadísticos robustos. SAS ofrece procedimientos avanzados como PROC MI (imputación múltiple) para análisis más sofisticados, pero en un contexto introductorio podríamos limitarnos a imputación simple o análisis de sensibilidad.
En SAS, para detectar valores faltantes podemos usar varias técnicas: PROC FREQ para listar la cantidad de missing por variable (en las tablas de frecuencia SAS incluye una fila “Missing” por defecto), o funciones como NMISS() para contar missing numéricos y CMISS() para contar missing tanto numéricos como carácter por observación. Ejemplo: PROC MEANS DATA=miData NMISS N; RUN; mostrará, para cada variable numérica, cuántos valores faltantes (NMISS) y cuántos no faltantes (N) hay. En un paso DATA, podemos usar IF MISSING(var) THEN ... para identificar o asignar valores. Es buena práctica crear un resumen de calidad de datos inicial: por ejemplo, una pequeña tabla con el porcentaje de valores faltantes por columna, para enfocar la limpieza donde sea necesario. Visual sugerida: mostrar un fragmento de log o salida de PROC FREQ o PROC MEANS donde se vea cómo SAS reporta los missing values (por ejemplo, “N Miss” en PROC MEANS).
- Aplicación de formatos a variables: Los formatos en SAS controlan cómo se muestran los datos, sin alterar su valor almacenado. Por ejemplo, un número 0.8 puede mostrarse como “80%” aplicando un formato de porcentaje, o un número 1234 puede mostrarse como “1,234” con formato de separador de miles. Para datos de fecha, los formatos son esenciales (un valor SAS de fecha es un número de días desde 1/1/1960; con un formato de fecha se muestra en formato legible). En SAS existen formatos predefinidos (p. ej., comma8.2 para números con coma y 2 decimales, date9. para fechas tipo DDMMMYYYY) y también se pueden crear formatos personalizados mediante PROC FORMAT.
Asignar formatos: Se realiza con la instrucción FORMAT ya sea en un paso DATA (asigna el formato de manera permanente al dataset) o dentro de un PROC (lo aplica temporalmente a la salida de ese procedimiento). Ejemplo: si tenemos una variable numérica edad y la queremos sin decimales, podemos definir en un paso DATA FORMAT edad 8.; (8: ancho, 0 decimales) para que los PROC futuros la muestren sin decimales. Si quisiéramos mostrar “H” como "Hombre" y "M" como "Mujer" en una variable sexo, definimos un formato de valores:
PROC FORMAT;
VALUE $sexoFmt
"F" = "Femenino"
"M" = "Masculino";
RUN;
DATA datos2;
SET datos1;
FORMAT sexo $sexoFmt.; /* Asigna formato personalizado */
RUN;
Ahora la variable sexo almacenará H/M pero al listarla aparecerá “Hombre”/“Mujer”. (Obsérvese el punto después del nombre del formato al asignarlo ). Si en vez de en el Data Step, aplicamos FORMAT sexo $sexoFmt.; dentro de un PROC PRINT o PROC FREQ , el dataset original no guarda esa asociación una vez termine el proc. Esta diferencia permanente vs temporal es importante en SAS .
Además de legibilidad, los formatos se pueden usar para agrupar valores. Por ejemplo, podríamos definir rangos: PROC FORMAT; VALUE rangoedad 0-17="Menor" 18-64="Adulto" 65-high="Senior"; RUN; y luego aplicar format edad rangoedad.; para categorizar edades en esos grupos al mostrar. SAS también reconoce informats (formato de entrada) para leer datos; por ejemplo al importar con Data Step se usa INPUT fecha DDMMYY10. para leer caracteres "31/12/2020" como fecha SAS. Aunque en este taller no profundizaremos en informats personalizados, es bueno saber que existen.
Visual sugerida: un cuadro comparativo con ejemplos de variable sin formato vs. con formato (p. ej., fecha cruda vs. fecha con format date9., número crudo vs. con format comma8.2). También se puede incluir una captura de la ventana Results de SAS Studio mostrando un PROC PRINT con y sin formato aplicado para ilustrar la diferencia.
Uso de filtros (subsetting de datos): Filtrar datos significa quedarnos solo con registros que cumplen cierta condición, ya sea para análisis o para enfocar la limpieza. En SAS podemos filtrar de dos maneras principales:
En un paso DATA, usando una sentencia IF (o SUBSET especial) para controlar qué observaciones se pasan al output. Por ejemplo:
/* Filtrar datos usando DATA step - crear subset de mayores de edad */
DATA work.mayores;
SET work.datos;
IF edad >= 18;
RUN;
/* Verificar el resultado */
PROC PRINT DATA=work.mayores (OBS=5);
TITLE 'Primeros 5 registros de mayores de edad';
RUN;
 Figura 6. Tabla resultante tras filtrar en Data Step (dataset MAYORES con edad ≥ 18).
Figura 6. Tabla resultante tras filtrar en Data Step (dataset MAYORES con edad ≥ 18).Esto leerá el dataset PERSONAS y escribirá en MAYORES solo aquellos con edad >= 18 (los que no cumplan la condición se descartan automáticamente, porque la condición IF en Data Step, si es falsa, implícitamente omite la salida de esa observación).
- En un paso PROC, usando la cláusula WHERE. Por ejemplo:
PROC PRINT DATA=personas;
WHERE sexo="F" AND salario > 50000;
RUN;
Listará únicamente las personas de sexo femenino con salario mayor a 50k. La ventaja de WHERE es que filtra a nivel del procedimiento sin crear un dataset separado, y funciona para la mayoría de PROC (SORT, MEANS, FREQ, etc.).
SAS Studio también permite filtros interactivos: al abrir un dataset en la vista de tabla, se pueden aplicar filtros rápidos (por ejemplo, clic derecho en una columna > Filter). Esto genera internamente una cláusula WHERE. Para propósitos de código reproducible, recomendamos usar IF/WHERE en la sintaxis. Ejercicio propuesto: tomar el dataset importado en la sección previa y filtrar, por ejemplo, casos de una cierta categoría. Preguntar a los participantes: “¿Cómo obtendríamos solo las ventas del año 2023?” y guiarlos a responder usando WHERE year(fecha)=2023 en un PROC, o IF year(fecha)=2023 en un paso DATA, dependiendo si quieren un subset temporal o permanente.
Otro uso de filtros en limpieza es aislar registros "sospechosos". Por ejemplo: “¿Cuáles registros tienen monto negativo?”. Se puede resolver con un PROC PRINT filtrando por condición:
/* Filtrar registros con monto negativo para identificar problemas */
PROC PRINT DATA=work.datos;
WHERE monto < 0;
TITLE 'Registros con monto negativo (problemas de calidad)';
RUN;
Si el resultado muestra errores de captura, podríamos decidir corregir o excluir esos registros.
Recursos recomendados: Revisar la documentación de WHERE statement en SAS Help Center (incluye operadores lógicos, comodines, etc.), y la sección de subsetting data del libro SAS Programming 1. Un buen material de referencia es el tip “Las funciones numéricas de SAS ignoran los valores faltantes” en la Comunidad SAS en español , que aunque se enfoca en funciones, aprovecha para ilustrar cómo SAS trata missing en filtros y cálculos. Para profundizar en formatos, consultar la documentación oficial de PROC FORMAT y el capítulo de formatos en SAS® 9.4 Language Reference (disponible en línea).
Ejemplos prácticos de limpieza
A continuación, una batería de ejemplos breves y explicados. Puedes copiarlos y adaptarlos a tu dataset. Asumimos un dataset de trabajo llamado work.datos con variables de ejemplo como id, fecha, monto, sexo, edad, categoria y pais.
- Imputar valores faltantes numéricos con la mediana (por grupo):
/* Calcula mediana por grupo y luego reemplaza missing */
PROC MEANS DATA=work.datos NOPRINT;
CLASS categoria;
VAR monto;
OUTPUT OUT=medianas_por_cat MEDIAN(monto)=med_monto;
RUN;
DATA work.datos_imp;
MERGE work.datos medianas_por_cat;
BY categoria;
IF missing(monto) THEN monto = med_monto;
DROP _TYPE_ _FREQ_ med_monto;
RUN;
- Imputar valores faltantes carácter con un valor por defecto:
DATA work.datos;
SET work.datos;
IF missing(pais) THEN pais = 'Desconocido';
RUN;
- Reemplazar outliers usando winsorización (percentiles 1 y 99):
/* Obtiene percentiles y recorta valores extremos */
PROC UNIVARIATE DATA=work.datos NOPRINT;
VAR monto;
OUTPUT OUT=pctl PCTLPTS=1 99 PCTLPRE=P_;
RUN;
DATA work.datos_win;
IF _N_=1 THEN SET pctl;
SET work.datos;
IF monto < P_1 THEN monto=P_1;
ELSE IF monto > P_99 THEN monto=P_99;
DROP P_:;
RUN;
- Crear variables derivadas (año y mes desde fecha; monto_iva):
DATA work.datos;
SET work.datos;
anio = YEAR(fecha);
mes = MONTH(fecha);
monto_iva = monto * 1.18; /* IVA 18% */
RUN;
- Normalizar texto: pasar a mayúsculas, quitar espacios a los lados y dentro:
DATA work.datos;
SET work.datos;
categoria = COMPBL(STRIP(UPCASE(categoria))); /* quita dobles espacios, recorta y mayúsculas */
pais = PROPCASE(STRIP(pais),' '); /* Capitaliza cada palabra */
RUN;
- Estandarizar categorías parecidas (mapeo por formato):
PROC FORMAT;
VALUE $catmap
'ELEC','ELECTR','ELECTRONICA' = 'ELECTRONICA'
'HOGAR','CASA' = 'HOGAR'
OTHER = [UPCASE.];
RUN;
DATA work.datos;
SET work.datos;
categoria_std = PUT(categoria,$catmap.);
RUN;
- Convertir tipos: texto a número y texto a fecha SAS:
DATA work.datos;
SET work.datos;
monto_num = INPUT(monto_char, BEST12.);
fecha_num = INPUT(fecha_char, DDMMYY10.);
FORMAT fecha_num DATE9.;
RUN;
- Filtrar y crear dataset limpio con reglas múltiples:
DATA work.datos_limpios;
SET work.datos;
/* Reglas: monto positivo, edad 18-99, fecha no futura */
IF monto > 0 AND 18 <= edad <= 99 AND fecha <= TODAY();
RUN;
- Quitar duplicados por
idconservando el último por fecha:
PROC SORT DATA=work.datos;
BY id fecha;
RUN;
DATA work.datos_nodup;
SET work.datos;
BY id;
IF LAST.id; /* conserva el último por id */
RUN;
- Rellenar hacia adelante (forward fill) dentro de cada ID:
PROC SORT DATA=work.datos;
BY id fecha;
RUN;
DATA work.ffill;
SET work.datos;
BY id;
RETAIN valor_ff;
IF FIRST.id THEN valor_ff = .;
IF NOT MISSING(valor) THEN valor_ff = valor;
RUN;
- Resumen rápido de calidad (missing y básicos por variable):
PROC MEANS DATA=work.datos N NMISS MEAN MIN P25 MEDIAN P75 MAX MAXDEC=2;
RUN;
PROC FREQ DATA=work.datos NLEVELS; /* categorías y niveles */
TABLES _CHARACTER_ / MISSING;
RUN;
- Reporte de filas “sospechosas” a CSV para revisión manual:
/* Exporta casos atípicos o inválidos */
PROC EXPORT DATA=work.datos (WHERE=(monto<0 OR edad>120 OR MISSING(id)))
OUTFILE="/home/usuario/out/anomalias.csv"
DBMS=CSV REPLACE;
RUN;
4. Validación de datos (inconsistencias, tipos de datos y validaciones lógicas)
La validación de datos se refiere a comprobar que los datos importados y limpios cumplen con las reglas de integridad esperadas: valores dentro de rangos lógicos, tipos de datos correctos, ausencia de duplicados indebidos, consistencia entre variables relacionadas, etc. En este sub-bloque enseñaremos métodos para detectar inconsistencias y asegurar la calidad antes de proceder a análisis complejos. Es un paso crucial para evitar basar decisiones en datos erróneos.
Control de tipos de datos: En SAS, cada variable es numérica o carácter. Un problema común al importar es que ciertos campos numéricos puedan haber quedado como carácter (texto) debido a valores atípicos o símbolos en los datos fuente. Para validar tipos:
Use PROC CONTENTS para listar todas las variables con sus tipos y longitudes, asegurando que, por ejemplo, variables llamadas ID o Cantidad sean numéricas si pretendemos hacer cálculos con ellas. Si alguna aparece como char injustificadamente, hay que convertirla. La conversión se logra en un paso DATA (nuevo_num = input(varChar, BEST12.); convierte texto numérico a número, o texto = put(varNum, 8.); viceversa).
Verifique también formatos asociados: si una variable fecha se importó como numérica sin formato de fecha, conviene asignarle un formato de fecha para interpretarla correctamente en outputs.
Si se esperan solo ciertos valores de texto (por ejemplo, códigos "A","B","C"), conviene revisar que no haya valores inesperados o errores de tipeo. Un PROC FREQ sobre esa variable listará todos los valores distintos; cualquier valor fuera del conjunto esperado indica un posible error de captura. Esto conecta con inconsistencias.
Detección de inconsistencias y outliers: Considere qué reglas de negocio o lógicas deben cumplir sus datos. Por ejemplo:
Rangos válidos: Si la edad de una persona debe estar entre 0 y 120, listar cualquier registro fuera de ese rango. Por ejemplo:
/* Detectar edades fuera de rango válido */
PROC PRINT DATA=work.datos;
WHERE edad < 0 OR edad > 120;
TITLE 'Registros con edad fuera de rango (< 0 o > 120)';
RUN;
Igualmente para fechas (fechas futuras en datos históricos, fechas de nacimiento lógicas, etc.) o montos negativos si no deben existir. Se pueden crear filtros de validación con condiciones lógicas para generar reportes de anomalías. Incluso es posible en un paso DATA hacer:
/* Crear dataset con todas las anomalías detectadas */
DATA work.anomalias;
SET work.datos;
IF edad < 0 OR edad > 120 OR salario < 0 THEN OUTPUT;
RUN;
y luego revisar anomalías para ver todos los registros problemáticos a corregir.
Valores faltantes en campos obligatorios: Si ciertas variables son críticas (por ejemplo, identificador único, fecha principal), ningún registro debería tenerlas en missing. Una validación es comprobar con PROC FREQ si el count de missing en esas variables es cero; si no, esos registros deben atenderse (completar o eliminar). En SAS podemos incluso poner constraints de integridad en datasets permanentes (usando PROC DATASETS o en SQL CREATE TABLE), pero en este nivel basta la comprobación manual.
Consistencia entre variables: Revisar relaciones lógicas: por ejemplo, si tenemos variables Fecha_Inicio y Fecha_Fin, debería cumplirse siempre Fecha_Fin ≥ Fecha_Inicio. Para validar eso en SAS:
/* Validar consistencia entre fechas relacionadas */
PROC PRINT DATA=work.datos;
WHERE Fecha_fin < Fecha_inicio;
TITLE 'Registros con fechas inconsistentes (fin < inicio)';
RUN;
Otro ejemplo: en un dataset de estudiantes, si hay una variable Nivel (pregrado, posgrado) y otra Carrera, podríamos verificar que las carreras correspondan al nivel correcto. Estas comprobaciones son específicas al contexto de datos y deben definirse caso por caso.
- Duplicados indebidos: Si se espera que cierta clave identificadora sea única (por ejemplo, un número de DNI, o un código de transacción), hay que asegurarlo. SAS permite detectar duplicados con PROC SORT + opción NODUPKEY:
/* Detectar y separar registros duplicados por ID */
PROC SORT DATA=work.datos NODUPKEY DUPOUT=work.dupes;
BY id;
RUN;
Esto ordenará por id y cualquier duplicado lo enviará al dataset dupes. Tras ejecutarlo, si dupes contiene observaciones, significa que ese id aparecía más de una vez. Alternativamente, con PROC FREQ podemos crear una tabla de frecuencias y detectar conteos > 1:
/* Contar frecuencias de ID para detectar duplicados */
PROC FREQ DATA=work.datos;
TABLES id / NOCUM NOPERCENT OUT=work.freqs;
RUN;
/* Mostrar solo IDs que aparecen más de una vez */
DATA work.duplicados;
SET work.freqs;
IF COUNT > 1;
RUN;
Integridad referencial (si aplica): En casos de múltiples tablas (no mucho en este taller, pero mencionar), SAS no impide por defecto que, por ejemplo, haya un código en tabla de hechos que no esté en la tabla de dimensión. La validación referencial se haría con procedimientos como PROC SQL realizando un left join y buscando valores faltantes en la tabla relacionada, o usando formatos personalizados para marcar valores válidos y luego un PUT que devuelva 'Other' si no encuentra coincidencia.
Validación mediante código vs. herramientas: Las herramientas SAS Data Quality (fuera del alcance aquí) pueden automatizar algunas validaciones, pero en SAS Base nosotros mismos escribimos las reglas. Una metodología recomendable es crear reportes de validación: usar PROC MEANS/FREQ para escanear estadísticas inusuales, usar PROC PRINT con condiciones para listar registros anómalos, etc. Por ejemplo, “Perfilado de datos” con PROC UNIVARIATE nos puede mostrar valores mínimos y máximos sorprendentes rápidamente .
Acciones correctivas: Identificada una inconsistencia, decidimos cómo proceder: corregir (si sabemos la fuente del error), excluir del análisis, o al menos documentar. Por ejemplo, podríamos decidir excluir duplicados de id dejando solo el primero – eso se implementaría con una combinación de sort y data step o usando FIRST.LAST. logic en BY-group processing. Lo importante es que ninguna supuesta "limpieza" se haga silenciosamente sin entender el impacto; por ello, documentar en el código con comentarios cada corrección de datos.
Ejemplos prácticos de validación
A continuación, una colección de ejemplos listos para usar. Asumimos un dataset work.datos con variables como id, fecha, monto, edad, sexo, categoria, pais, email, etc.
1. Validar tipos de datos y generar reporte de variables:
/* Obtener información detallada de tipos y formatos */
PROC CONTENTS DATA=work.datos SHORT;
RUN;
/* Identificar variables que deberían ser numéricas pero están como texto */
DATA work.tipos_sospechosos;
SET work.datos;
/* Verificar si campos que parecen numéricos son realmente texto */
es_num_monto = NOT MISSING(INPUT(monto, ?? BEST12.));
es_num_edad = NOT MISSING(INPUT(edad, ?? BEST12.));
IF NOT (es_num_monto AND es_num_edad) THEN OUTPUT;
RUN;
2. Validar rangos numéricos con reportes detallados:
/* Crear reporte completo de valores fuera de rango */
DATA work.rangos_invalidos;
SET work.datos;
LENGTH problema $100 valor_actual $50;
/* Edad debe estar entre 16 y 99 */
IF edad < 16 OR edad > 99 THEN DO;
problema = 'Edad fuera de rango válido (16-99)';
valor_actual = PUT(edad, BEST12.);
OUTPUT;
END;
/* Monto debe ser positivo */
IF monto <= 0 THEN DO;
problema = 'Monto debe ser positivo';
valor_actual = PUT(monto, DOLLAR12.2);
OUTPUT;
END;
/* Porcentajes entre 0 y 100 */
IF 0 < porcentaje_descuento < 1 THEN DO;
problema = 'Porcentaje parece estar en decimal (0-1) en lugar de 0-100';
valor_actual = PUT(porcentaje_descuento, PERCENT8.2);
OUTPUT;
END;
RUN;
/* Mostrar resumen de problemas encontrados */
PROC FREQ DATA=work.rangos_invalidos;
TABLES problema / NOCUM;
RUN;
3. Validar fechas y detectar inconsistencias temporales:
/* Validaciones completas de fechas */
DATA work.fechas_invalidas;
SET work.datos;
LENGTH problema $100;
/* Fechas no pueden ser futuras para datos históricos */
IF fecha_nacimiento > TODAY() THEN DO;
problema = 'Fecha de nacimiento futura';
OUTPUT;
END;
/* Fecha de inicio debe ser anterior a fecha fin */
IF fecha_inicio > fecha_fin THEN DO;
problema = 'Fecha inicio posterior a fecha fin';
OUTPUT;
END;
/* Edad calculada vs edad reportada */
edad_calculada = INT((TODAY() - fecha_nacimiento) / 365.25);
IF ABS(edad_calculada - edad) > 1 THEN DO;
problema = 'Inconsistencia entre edad reportada y fecha nacimiento';
OUTPUT;
END;
/* Fechas muy antiguas (posibles errores de entrada) */
IF fecha_nacimiento < '01JAN1900'D THEN DO;
problema = 'Fecha de nacimiento demasiado antigua';
OUTPUT;
END;
RUN;
4. Validar formatos de texto y patrones comunes:
/* Validar emails, teléfonos y códigos */
DATA work.formatos_invalidos;
SET work.datos;
LENGTH problema $100 campo $50;
/* Validar formato básico de email */
IF email NE '' AND (INDEX(email, '@') = 0 OR INDEX(email, '.') = 0) THEN DO;
problema = 'Email sin formato válido';
campo = email;
OUTPUT;
END;
/* Validar longitud de DNI/ID */
IF LENGTH(STRIP(id)) NOT IN (8, 11) THEN DO;
problema = 'ID no tiene longitud esperada (8 o 11 dígitos)';
campo = id;
OUTPUT;
END;
/* Validar códigos de país (2 o 3 letras) */
IF codigo_pais NE '' AND (LENGTH(STRIP(codigo_pais)) NOT IN (2, 3) OR
ANYDIGIT(codigo_pais) > 0) THEN DO;
problema = 'Código país inválido';
campo = codigo_pais;
OUTPUT;
END;
/* Detectar caracteres especiales inesperados en nombres */
IF ANYDIGIT(nombre) > 0 OR ANYPUNCT(nombre) > 0 THEN DO;
problema = 'Nombre contiene números o símbolos';
campo = nombre;
OUTPUT;
END;
RUN;
5. Detectar valores atípicos estadísticamente:
/* Identificar outliers usando método IQR */
PROC MEANS DATA=work.datos NOPRINT;
VAR monto salario;
OUTPUT OUT=work.estadisticas
Q1(monto salario)=Q1_monto Q1_salario
Q3(monto salario)=Q3_monto Q3_salario;
RUN;
DATA work.outliers_estadisticos;
IF _N_ = 1 THEN SET work.estadisticas;
SET work.datos;
/* Calcular límites IQR */
iqr_monto = Q3_monto - Q1_monto;
limite_inf_monto = Q1_monto - 1.5 * iqr_monto;
limite_sup_monto = Q3_monto + 1.5 * iqr_monto;
iqr_salario = Q3_salario - Q1_salario;
limite_inf_salario = Q1_salario - 1.5 * iqr_salario;
limite_sup_salario = Q3_salario + 1.5 * iqr_salario;
/* Marcar outliers */
IF monto < limite_inf_monto OR monto > limite_sup_monto OR
salario < limite_inf_salario OR salario > limite_sup_salario THEN OUTPUT;
DROP Q1_: Q3_: iqr_: limite_:;
RUN;
6. Validar completitud y patrones de datos faltantes:
/* Análisis completo de missingness */
PROC MEANS DATA=work.datos NMISS N;
VAR _NUMERIC_;
RUN;
/* Patrones de datos faltantes */
DATA work.patrones_missing;
SET work.datos;
LENGTH patron_missing $50;
/* Crear patrón de variables faltantes */
patron_missing = '';
IF MISSING(nombre) THEN patron_missing = STRIP(patron_missing) || 'N';
ELSE patron_missing = STRIP(patron_missing) || '.';
IF MISSING(edad) THEN patron_missing = STRIP(patron_missing) || 'E';
ELSE patron_missing = STRIP(patron_missing) || '.';
IF MISSING(salario) THEN patron_missing = STRIP(patron_missing) || 'S';
ELSE patron_missing = STRIP(patron_missing) || '.';
IF MISSING(fecha_nacimiento) THEN patron_missing = STRIP(patron_missing) || 'F';
ELSE patron_missing = STRIP(patron_missing) || '.';
/* Solo mantener registros con al menos un missing */
IF patron_missing NE '....';
RUN;
PROC FREQ DATA=work.patrones_missing;
TABLES patron_missing / NOCUM;
TITLE 'Patrones de datos faltantes (N=Nombre, E=Edad, S=Salario, F=Fecha)';
RUN;
7. Validar consistencia entre variables relacionadas:
/* Validaciones de consistencia lógica */
DATA work.inconsistencias_logicas;
SET work.datos;
LENGTH inconsistencia $100;
/* Salario vs nivel educativo */
IF nivel_educacion = 'DOCTORADO' AND salario < 50000 THEN DO;
inconsistencia = 'Salario bajo para nivel doctoral';
OUTPUT;
END;
/* Experiencia vs edad */
años_experiencia = INT((TODAY() - fecha_inicio_laboral) / 365.25);
IF años_experiencia > (edad - 16) THEN DO;
inconsistencia = 'Más experiencia que años posibles de trabajo';
OUTPUT;
END;
/* Estado civil vs edad */
IF estado_civil = 'CASADO' AND edad < 16 THEN DO;
inconsistencia = 'Menor de edad casado';
OUTPUT;
END;
/* Categoría vs valores asociados */
IF categoria = 'VIP' AND (monto_compras < 10000 OR años_cliente < 2) THEN DO;
inconsistencia = 'Cliente VIP con bajo volumen o antigüedad';
OUTPUT;
END;
RUN;
8. Crear reporte maestro de validación:
/* Reporte consolidado de calidad de datos */
PROC SQL;
CREATE TABLE work.reporte_calidad AS
SELECT
'Registros totales' AS metrica,
COUNT(*) AS valor,
'' AS observaciones
FROM work.datos
UNION ALL
SELECT
'IDs únicos' AS metrica,
COUNT(DISTINCT id) AS valor,
CASE WHEN COUNT(DISTINCT id) < COUNT(*)
THEN 'HAY DUPLICADOS'
ELSE 'OK' END AS observaciones
FROM work.datos
UNION ALL
SELECT
'Edades faltantes' AS metrica,
SUM(CASE WHEN MISSING(edad) THEN 1 ELSE 0 END) AS valor,
PUT(SUM(CASE WHEN MISSING(edad) THEN 1 ELSE 0 END)/COUNT(*)*100, 5.1)
|| '% del total' AS observaciones
FROM work.datos
UNION ALL
SELECT
'Emails inválidos' AS metrica,
SUM(CASE WHEN email NE '' AND INDEX(email,'@')=0 THEN 1 ELSE 0 END) AS valor,
'Revisar formatos' AS observaciones
FROM work.datos;
QUIT;
PROC PRINT DATA=work.reporte_calidad NOOBS;
TITLE 'Reporte de Calidad de Datos';
RUN;
9. Validación automática con macros (ejemplo avanzado):
/* Macro para validar rangos automáticamente */
%MACRO validar_rango(dataset, variable, min_val, max_val);
DATA &dataset._&variable._check;
SET &dataset;
IF NOT (&min_val <= &variable <= &max_val) THEN DO;
variable_problema = "&variable";
valor_encontrado = &variable;
rango_esperado = "&min_val a &max_val";
OUTPUT;
END;
KEEP id variable_problema valor_encontrado rango_esperado;
RUN;
%IF %SYSFUNC(EXIST(&dataset._&variable._check)) %THEN %DO;
PROC PRINT DATA=&dataset._&variable._check;
TITLE "Problemas de rango en variable &variable";
RUN;
%END;
%MEND;
/* Usar la macro */
%validar_rango(work.datos, edad, 16, 99);
%validar_rango(work.datos, monto, 0, 999999);
Ejercicio/Interacción sugerido: Presentar a los asistentes un pequeño conjunto de datos con errores sembrados (p. ej., edad = 200, salario = -100, género = "X", ID duplicado) y pedir que identifiquen los problemas aplicando filtros/validaciones. Esto se puede hacer en grupo, discutiendo qué salida arrojaría cada check. Luego mostrar el código SAS y su resultado atrapando cada error. Esto refuerza la importancia de la validación sistemática.
Recursos adicionales
- Pruebas de integridad y precisión de los datos (FasterCapital) · Introducción general a criterios de validación, útil para contextualizar controles.
- PROC SORT — eliminación de duplicados con
NODUPKEY(SAS Help) · Revisión oficial de la opción para quedarnos con la primera fila por clave.- SAS Blogs — Limpieza de datos (Ron Cody) · Trucos y técnicas de “data cleaning” desde SAS Press/Blogs.
- SAS Communities Library — Data Quality en Viya (serie) · Fundamentos y reglas de calidad en la librería de comunidades.
5. Conectarse a una base de datos PostgreSQL usando Neon
En esta sección aprenderemos a conectar SAS con una base de datos PostgreSQL alojada en Neon (https://neon.tech), un servicio de base de datos PostgreSQL serverless en la nube. Esto nos permite trabajar con datos que están almacenados externamente y acceder a ellos directamente desde SAS sin necesidad de importar archivos estáticos.
¿Qué es Neon y por qué usarlo?
Neon es una plataforma moderna de PostgreSQL que ofrece:
- ✅ Configuración rápida - Base de datos lista en segundos
- ✅ Escalado automático - Se adapta al uso real
- ✅ Plan gratuito generoso - Perfecto para aprendizaje y desarrollo
- ✅ Compatibilidad completa con PostgreSQL - Funciona con SAS sin problemas
Para este taller, utilizaremos la siguiente conexión de ejemplo:
postgresql://neondb_owner:npg_6aPfyiLSs0FW@ep-lucky-sky-agtari87.c-2.eu-central-1.aws.neon.tech/neondb?channel_binding=require&sslmode=require
Configuración de la conexión en SAS
1. Establecer la conexión con LIBNAME:
/* Configurar conexión a PostgreSQL en Neon */
LIBNAME neondb POSTGRES
SERVER="ep-lucky-sky-agtari87.c-2.eu-central-1.aws.neon.tech"
PORT=5432
DATABASE=neondb
USER="neondb_owner"
PASSWORD="npg_6aPfyiLSs0FW"
SCHEMA=public
SSL_REQUIRE=YES;
2. Verificar la conexión:
/* Verificar que la conexión funciona */
PROC DATASETS LIBRARY=neondb;
RUN;
/* Listar todas las tablas disponibles */
PROC SQL;
SELECT memname AS tabla_nombre, memtype AS tipo
FROM dictionary.tables
WHERE libname = 'NEONDB'
ORDER BY memname;
QUIT;
Trabajando con datos en la base de datos remota
3. Consultar datos existentes:
/* Ver estructura de una tabla */
PROC CONTENTS DATA=neondb.empleados;
RUN;
/* Consulta simple - primeros 10 registros */
PROC SQL OUTOBS=10;
SELECT * FROM neondb.empleados;
QUIT;
/* Consulta con filtros y agregaciones */
PROC SQL;
SELECT departamento,
COUNT(*) AS total_empleados,
AVG(salario) AS salario_promedio,
MIN(fecha_ingreso) AS primer_ingreso
FROM neondb.empleados
WHERE activo = 1
GROUP BY departamento
ORDER BY salario_promedio DESC;
QUIT;
4. Crear tablas en la base de datos:
/* Crear una nueva tabla directamente en PostgreSQL */
PROC SQL;
CONNECT TO POSTGRES (
SERVER="ep-lucky-sky-agtari87.c-2.eu-central-1.aws.neon.tech"
PORT=5432
DATABASE=neondb
USER="neondb_owner"
PASSWORD="npg_6aPfyiLSs0FW"
SSL_REQUIRE=YES
);
EXECUTE (
CREATE TABLE IF NOT EXISTS ventas_sas (
id SERIAL PRIMARY KEY,
producto VARCHAR(100),
cantidad INTEGER,
precio DECIMAL(10,2),
fecha_venta DATE,
vendedor VARCHAR(50),
region VARCHAR(30)
)
) BY POSTGRES;
DISCONNECT FROM POSTGRES;
QUIT;
5. Insertar datos desde SAS a PostgreSQL:
/* Crear datos de ejemplo en SAS */
DATA work.ventas_ejemplo;
LENGTH producto $100 vendedor $50 region $30;
INPUT producto $ cantidad precio fecha_venta :date9. vendedor $ region $;
DATALINES;
Laptop_Pro 2 1299.99 15MAR2024 Juan_Perez Norte
Monitor_4K 5 599.50 16MAR2024 Ana_Garcia Sur
Teclado_RGB 10 89.99 17MAR2024 Carlos_Lopez Centro
Mouse_Gaming 8 45.75 18MAR2024 Maria_Ruiz Este
Webcam_HD 3 129.00 19MAR2024 Pedro_Sanchez Norte
;
RUN;
/* Insertar datos en PostgreSQL */
DATA neondb.ventas_sas;
SET work.ventas_ejemplo;
RUN;
6. Consultas avanzadas mezclando datos locales y remotos:
/* Crear dataset local con información adicional */
DATA work.info_regiones;
LENGTH region $30 pais $20 zona_horaria $10;
INPUT region $ pais $ zona_horaria $;
DATALINES;
Norte Mexico GMT-6
Sur Chile GMT-3
Centro Colombia GMT-5
Este Brasil GMT-3
;
RUN;
/* JOIN entre datos remotos (PostgreSQL) y locales (SAS) */
PROC SQL;
CREATE TABLE work.ventas_completas AS
SELECT v.*, r.pais, r.zona_horaria,
v.cantidad * v.precio AS total_venta
FROM neondb.ventas_sas v
LEFT JOIN work.info_regiones r
ON v.region = r.region;
QUIT;
PROC PRINT DATA=work.ventas_completas;
TITLE 'Ventas con información geográfica completa';
RUN;
Ejemplos prácticos de análisis con datos remotos
7. Análisis de rendimiento por región:
/* Análisis de ventas por región */
PROC SQL;
CREATE TABLE work.resumen_regional AS
SELECT region,
COUNT(*) AS num_ventas,
SUM(cantidad) AS total_unidades,
SUM(cantidad * precio) AS ingresos_totales,
AVG(precio) AS precio_promedio,
MIN(fecha_venta) AS primera_venta,
MAX(fecha_venta) AS ultima_venta
FROM neondb.ventas_sas
GROUP BY region
ORDER BY ingresos_totales DESC;
QUIT;
/* Crear gráfico de ingresos por región */
PROC SGPLOT DATA=work.resumen_regional;
VBAR region / RESPONSE=ingresos_totales
DATALABEL=ingresos_totales;
TITLE 'Ingresos Totales por Región';
XAXIS LABEL='Región';
YAXIS LABEL='Ingresos ($)' FORMAT=DOLLAR12.;
RUN;
8. Monitoreo de la base de datos:
/* Obtener estadísticas de las tablas */
PROC SQL;
CONNECT TO POSTGRES (
SERVER="ep-lucky-sky-agtari87.c-2.eu-central-1.aws.neon.tech"
PORT=5432
DATABASE=neondb
USER="neondb_owner"
PASSWORD="npg_6aPfyiLSs0FW"
SSL_REQUIRE=YES
);
CREATE TABLE work.estadisticas_db AS
SELECT * FROM CONNECTION TO POSTGRES (
SELECT schemaname, tablename, n_tup_ins, n_tup_upd, n_tup_del
FROM pg_stat_user_tables
ORDER BY tablename
);
DISCONNECT FROM POSTGRES;
QUIT;
PROC PRINT DATA=work.estadisticas_db;
TITLE 'Estadísticas de uso de tablas en PostgreSQL';
RUN;
9. Backup y exportación de datos:
/* Exportar tabla completa a CSV como backup */
PROC EXPORT DATA=neondb.ventas_sas
OUTFILE="/home/usuario/backup/ventas_backup_%sysfunc(today(),yymmddn8.).csv"
DBMS=CSV REPLACE;
RUN;
/* Crear vista materializada para consultas frecuentes */
PROC SQL;
CONNECT TO POSTGRES (
SERVER="ep-lucky-sky-agtari87.c-2.eu-central-1.aws.neon.tech"
PORT=5432
DATABASE=neondb
USER="neondb_owner"
PASSWORD="npg_6aPfyiLSs0FW"
SSL_REQUIRE=YES
);
EXECUTE (
CREATE MATERIALIZED VIEW IF NOT EXISTS vista_ventas_resumen AS
SELECT
DATE_TRUNC('month', fecha_venta) as mes,
region,
COUNT(*) as num_ventas,
SUM(cantidad * precio) as ingresos
FROM ventas_sas
GROUP BY DATE_TRUNC('month', fecha_venta), region
) BY POSTGRES;
DISCONNECT FROM POSTGRES;
QUIT;
10. Limpieza y cierre de conexión:
/* Cerrar la conexión cuando termine el trabajo */
LIBNAME neondb CLEAR;
/* Mensaje de confirmación */
%PUT NOTE: Conexión a Neon PostgreSQL cerrada exitosamente;
Ventajas de usar PostgreSQL con SAS
✅ Datos centralizados - Una sola fuente de verdad para equipos
✅ Escalabilidad - Maneja grandes volúmenes de datos
✅ Seguridad - Control de acceso y encriptación
✅ Integridad - Transacciones ACID y restricciones
✅ Colaboración - Múltiples usuarios simultáneos
✅ Backup automático - Neon maneja respaldos
Consideraciones importantes
⚠️ Rendimiento de red - Consultas grandes pueden ser lentas por la red
⚠️ Costos de transferencia - Monitorear uso de datos
⚠️ Timeouts de conexión - Configurar adecuadamente en SAS
⚠️ Compatibilidad de tipos - Algunos tipos de PostgreSQL pueden requerir conversión
Ejercicio práctico: Conectarse a la base de datos Neon proporcionada, crear una tabla con datos de estudiantes (nombre, edad, carrera, promedio), insertar 5 registros de ejemplo, y realizar una consulta que muestre el promedio general por carrera. Luego crear un gráfico de barras con los resultados.
Recursos adicionales
- Neon Documentation - Guía completa para usar Neon PostgreSQL
Enlace: https://neon.tech/docs - SAS/ACCESS Interface to PostgreSQL - Documentación oficial de SAS
Enlace: https://documentation.sas.com/doc/en/pgmsascdc/v_027/acreldb/n0tupen8b6vybin1bsg8fzq4f6b7.htm - PostgreSQL Tutorial - Aprende SQL para PostgreSQL
Enlace: https://www.postgresqltutorial.com/ - SAS Communities - Database Connections - Foro de ayuda y ejemplos
Enlace: https://communities.sas.com/t5/SAS-Data-Management/bd-p/data_management